
Dear friends,
I am alarmed by the proposed cuts to U.S. funding for basic research, analyzed here, and the impact this would have for U.S. competitiveness in AI and other areas. Funding research that is openly shared benefits the whole world, but the nation it benefits most is the one where the research is done.
If not for funding for my early work in deep learning from the National Science Foundation (NSF) and Defense Advanced Research Projects Agency (DARPA), which disburse much of U.S. research funding, I would not have discovered lessons about scaling that led me to pitch starting Google Brain to scale up deep learning. I am worried that cuts to funding for basic science will lead the U.S. — and also the world — to miss out on the next set of ideas.
In fact, such funding benefits the U.S. more than any other nation. Scientific research brings the greatest benefit to the country where the work happens because (i) the new knowledge diffuses fastest within that country, and (ii) the process of doing research creates new talent for that nation.
Why does most innovation in generative AI still happen in Silicon Valley? Because two teams based in this area — Google Brain, which invented the transformer network, and OpenAI, which scaled it up — did a lot of the early work. Subsequently, team members moved to other nearby businesses, started competitors, or worked with local universities. Further, local social networks rapidly diffused the knowledge through casual coffee meetings, local conferences, and even children’s play dates, where parents of like-aged kids meet and discuss technical ideas. In this way, the knowledge spread faster within Silicon Valley than to other geographies.
In a similar vein, research done in the U.S. diffuses to others in the U.S. much faster than to other geographic areas. This is particularly true when the research is openly shared through papers and/or open source: If researchers have permission to talk about an idea, they can share much more information, such as tips and tricks for how to really make an algorithm work, more quickly. It also lets others figure out faster who can answer their questions. Diffusion of knowledge created in academic environments is especially fast. Academia tends to be completely open, and students and professors, unlike employees of many companies, have full permission to talk about their work.
Thus funding basic research in the U.S. benefits the U.S. most, and also benefits our allies. It is true that openness benefits our adversaries, too. But as a subcommittee of the U.S. House of Representatives committee on science, space, and technology points out, “... open sharing of fundamental research is [not] without risk. Rather, ... openness in research is so important to competitiveness and security that it warrants the risk that adversaries may benefit from scientific openness as well.”

Further, generative AI is evolving so rapidly that staying on the cutting edge is what’s really critical. For example, the fact that many teams can now train a model with GPT-3.5- or even GPT-4-level capability does not seem to be hurting OpenAI much, which is busy growing its business by developing the cutting-edge o4, Codex, GPT-4.1, and so on. Those who invent a technology get to commercialize it first, and in a fast-moving world, the cutting-edge technology is what’s most valuable. Studies like this one (albeit done while the internet was not as prevalent as it is today) also show how knowledge diffuses locally much faster than globally.
China was decisively behind the U.S. in generative AI when ChatGPT was first launched in 2022. However, China’s tech ecosystem is very open internally, and this has helped it to catch up over the past two years:
- There is ample funding for open academic research in China.
- China’s businesses such as DeepSeek and Alibaba have released cutting-edge, open-weights models. This openness at the corporate level accelerates diffusion of knowledge.
- China’s labor laws make non-compete agreements (which stop an employee from jumping ship to a competitor) relatively hard to enforce, and the work culture supports significant idea sharing among employees of different companies; this has made circulation of ideas relatively efficient.
While there’s also much about China that I would not seek to emulate, the openness of its tech ecosystem has helped it accelerate.
In 1945, Vannevar Bush’s landmark report “Science, The Endless Frontier” laid down key principles for public funding of U.S. research and talent development. Those principles enabled the U.S. to dominate scientific progress for decades. U.S. federal funding for science created numerous breakthroughs that have benefited the U.S. tremendously, and also the world, while training generations of domestic scientists, as well as immigrants who likewise benefit the U.S.
The good news is that this playbook is now well known. I hope many more nations will imitate it and invest heavily in science and talent. And I hope that, having pioneered this very successful model, the U.S. will not pull back from it by enacting drastic cuts to funding scientific research.
Andrew
A MESSAGE FROM DEEPLEARNING.AI AND SNOWFLAKE

We’re featured partners of Snowflake’s Dev Day 2025, a full day for AI and data practitioners to explore cutting-edge demos, make valuable contacts, and hear from top voices in the field (including Andrew Ng). See you on June 5! Register here
News

Claude 4 Advances Code Generation
Anthropic continued its tradition of building AI models that raise the bar in coding tasks.
What’s new: Anthropic launched Claude 4 Sonnet 4 and Claude Opus 4, the latest medium- and largest-size members of its family of general-purpose large language models. Both models offer an optional reasoning mode and can use multiple tools in parallel while reasoning. In addition, the company made generally available Claude Code, a coding agent previously offered as a research preview, along with a Claude Code software development kit.
- Input/output: Text, images, PDF files in (up to 200,000 tokens); text out (Claude Sonnet 4 up to 64,000 tokens, Claude Opus 4 up to 32,000 tokens)
- Features: Parallel tool use including computer use, selectable reasoning mode with visible reasoning tokens, multilingual (15 languages)
- Performance: Ranked Number One in LMSys WebDev Arena, state-of-the-art on SWE-bench and Terminal-bench
- Availability/price: Anthropic API, Amazon Bedrock, Google Cloud Vertex AI. Claude Sonnet 4 $3/$15 per million input/output tokens, Claude Opus 4 $15/$75 per million input/output tokens
- Undisclosed: Parameter counts, specific training methods and datasets
How it works: The team trained the Claude 4 models on a mix of publicly available information on the web as well as proprietary purchased data, data from Claude users who opted to share their inputs and outputs, and generated data. They fine-tuned the models to be helpful, honest, and harmless according to human and AI feedback.
- The models make reasoning tokens visible within limits. For especially lengthy chains of thought, an unspecified smaller model summarizes reasoning tokens.
- Given local file access, Claude Opus 4 can create and manipulate files to store information. For instance, prompted to maintain a knowledge base while playing a Pokémon video game, the model produced a guide to the game that offered advice such as, “If stuck, try OPPOSITE approach” and “Change Y-coordinate when horizontal movement fails.”
Results: Both Claude 4 models tied Google Gemini 2.5 Pro at the top of the LMSys WebDev Arena and achieved top marks for coding and agentic computer-use benchmarks in Anthropic’s tests.
- On SWE-bench Verified, which tests the model’s ability to solve software issues from GitHub, Claude Opus 4 succeeded 72.5 percent of the time, and Claude Sonnet 4 succeeded 72.7 percent of the time. The next best model, OpenAI o3, succeeded 70.3 percent of the time.
- Terminal-bench evaluates how well models work with the benchmark’s built-in agentic framework to perform tasks on a computer terminal. Claude Opus 4 succeeded 39.2 percent of the time and Claude Sonnet 4 succeeded 33.5 percent of the time, whereas the closest competitor, OpenAI GPT 4.1, succeeded 30.3 percent of the time. Using Claude Code as the agentic framework, Claude Opus 4 succeeded 43.2 percent of the time and Claude Sonnet 4 succeeded 35.5 percent of the time.
Why it matters: The new models extend LLM technology with parallel tool use, using external files as a form of memory, and staying on-task over unusually long periods of time. Early users have reported many impressive projects, including a Tetris clone built in one shot and a seven-hour stint refactoring Rakutan’s open-source code base.
We’re thinking: Prompting expert @elder_plinius published a text file that is purported to be Claude 4’s system prompt and includes some material that does not appear in Anthropic’s own publication of the prompts. It is instructive to see how it conditions the model for tool use, agentic behavior, and reasoning.

Google I/O Overdrive
Google revamped its roster of models, closed and open, and added more AI-powered features to its existing products.
What’s new: Google staged a parade of announcements at this year’s I/O developer conference. New offerings include improvements to Gemini 2.5 Pro and Gemini 2.5 Flash and a preview of Gemma 3n (all three generally available in June), the updated Veo 3 video generator (available via Flow, Google’s AI videography app, for paid subscribers to its AI Pro and Ultra services), and increasingly AI-powered search.
How it works: The I/O offerings spanned from public-facing products to developer tools.
- Google updated Gemini 2.5 Pro and the speedier Gemini 2.5 Flash with audio output, so both models now take in text, audio, images, and video and produce text and audio. In addition, they offer summaries of tokens produced while reasoning. Gemini-2.5-Pro-Preview-05-06, which topped the LMSys Text Arena and WebDev Arena (tied with Claude 4 Opus and Sonnet), lets users set a reasoning budget up to 128,000 tokens, enabling it to outperform OpenAI o3 and o4-mini (set to high effort) on math, coding, and multimodal benchmarks in Google’s tests. Gemini-2.5-Flash-Preview-05-20 uses 22 percent fewer tokens than its predecessor while ranking near the top of the LMSys Text Arena and WebDev Arena.
- The Veo 3 text-to-video generator produces 3840x2160-pixel video with audio (dialogue, sound effects, and music) with creative controls including the ability to add and remove objects and maintain consistent characters. It bested Kuaishu Kling 2.0, Runway Gen 3, and OpenAI Sora in Google’s comparisons.
- New members of Google’s Gemma 3 family of open-weights models, Gemma 3n 5B and 8B, are multilingual (over 140 languages), multimodal (text, vision, audio in; text out), and optimized for mobile platforms. Gemma-3n-E4B-it (8 billion parameters) ranks just ahead of Anthropic Claude 3.7 Sonnet in the LMSys Text Arena. Gemma 3n 5B and 8B are 1.5 times faster than their predecessors and require 2 gigabytes and 3 gigabytes of memory, respectively, thanks to techniques that include per-layer embeddings, key-value caching, conditional parameter loading (constraining active parameters to specific modalities at inference), and a Matryoshka Transformer design that dynamically activates nested sub-models. They’re available in preview via Google’s AI Studio, AI Edge, GenAI SDK, or MediaPipe.
- Google introduced several specialized AI tools and models. Jules is an autonomous, asynchronous, multi-agent coding assistant that clones repos into a secure virtual machine to perform tasks like writing tests, building features, and fixing bugs (available in public beta). SignGemma translates American sign language to text (previously ASL to English). MedGemma analyzes medical text and images (part of the open-weights collection Health AI Developer Foundations).
- Building on Google Search’s AI Overviews, Google is further building AI into search. Google Search’s AI Mode uses Gemini 2.5 to deliver a “deep search” mode that decomposes users’ questions into hundreds of sub-queries for analysis and visualization. Google plans to integrate AI Mode features into its core search product. In addition, Google Search’s AI Mode will gain Search Live (real-time, audio-enabled visual interaction via camera) and agentic features (for tasks such as purchasing tickets). Computer-use capabilities are coming to the Gemini API and Vertex AI.
Why it matters: Google is catching up with the Microsoft/OpenAI colossus on several fronts. The addition of audio output to Gemini and Gemma models fuels the rise of voice-to-voice and other audio applications and gives developers powerful new tools to build them. At the same time, Veo 3’s text-to-video-plus-audio output shows marked improvement over the previous version.
Behind the news: The number of tokens Google processed monthly has surged this year from 9.7 trillion last year to 480 trillion, a sign that its AI APIs and AI-infused products are rapidly gaining traction. Google’s progress contrasts with Apple’s ongoing struggles. Both share advantages in smartphones and app distribution. But, while Google has showcased a string of advanced models as well as early efforts to integrate them into legacy products, Apple’s organizational challenges have hampered its AI development. Now Apple must contend with OpenAI’s acquisition of LoveFrom, the startup founded by its former lead product designer Jony Ive.
We’re thinking: Google I/O 2025 was a strong showing of generative AI capabilities! There’s still work to be done to translate these innovations into compelling products, but the company now has a strong base for building numerous innovative products.
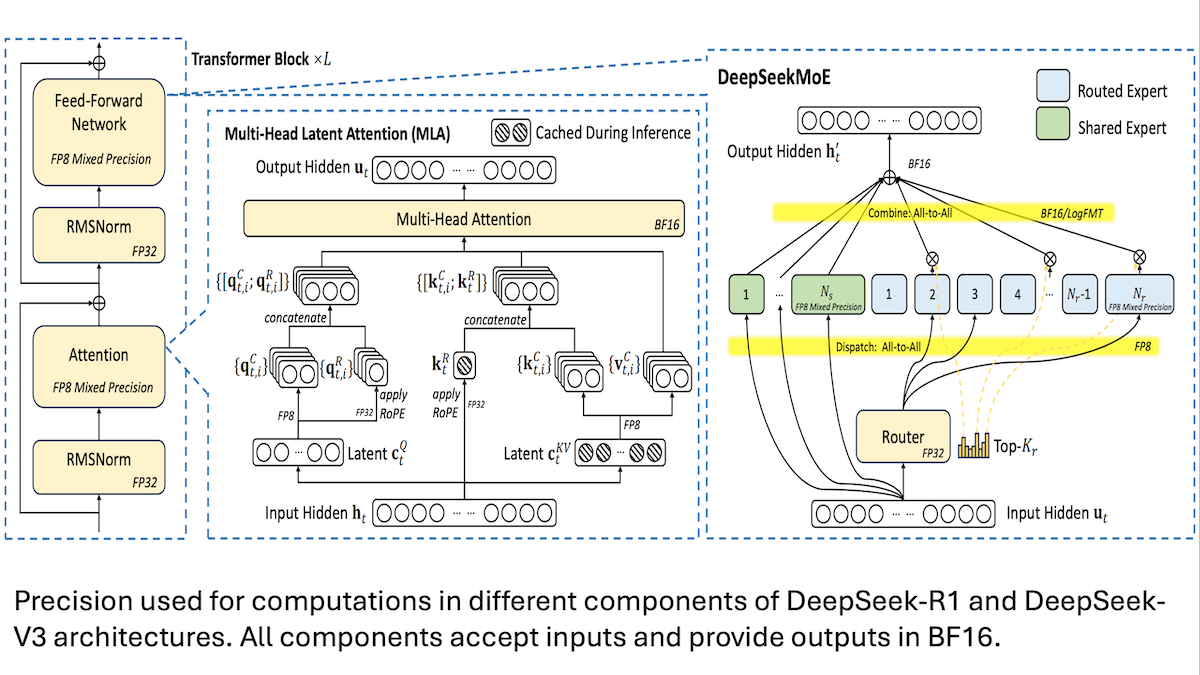
How DeepSeek Did It
DeepSeek made headlines late last year, when it built a state-of-the-art, open-weights large language model at a cost far lower than usual. The upstart developer shared new details about its method.
What’s new: Chenggang Zhao and colleagues at DeepSeek described software and hardware choices that reduced memory and processing requirements while building their groundbreaking mixture-of-experts models DeepSeek-R1 and DeepSeek-V3.
Mixture of experts (MoE) basics: The MoE architecture uses different subsets of a model’s parameters to process different inputs. Each MoE layer contains a group of neural networks, or experts, preceded by a routing module that learns to choose which one(s) to use based on the training example. In this way, different experts learn to specialize in different types of input.
How it works: The authors trained DeepSeek-R1 and DeepSeek-V3 using a cluster of 2,048 Nvidia H800 GPUs composed of nodes that contained 8 GPUs each. MoE requires less memory than dense architectures, since a given input activates only a portion of a model’s parameters. This enabled the authors to train DeepSeek-V3 on 250 GFLOPs per token, while Qwen 2.5 72B required 394 GFLOPs per token and Llama 3.1 405B required 2,448 GFLOPs per token.
- The authors built a mixed-precision training algorithm to reduce the memory requirements of training MoE models. They used FP8 (8-bit) numbers to perform computations including linear transformations and 16- or 32-bit precision to perform others such as computing embeddings. (They say DeepSeek-V3 was the first open LLM to have been trained using FP8.)
- The authors noticed that communication between GPUs inside a node was four times faster than communication between nodes. To ensure fast communication when routing tokens to experts, they limited the algorithm to process them within up to 4 nodes.
- To utilize GPUs more fully, they divided each GPU’s input data so the chip processes computation and communication at the same time. Specifically, the chip computes attention or MoE layers on one part of the data and simultaneously sends the other part of the data to other GPUs or aggregates it from other GPUs as necessary.
- To further save inference memory, the models use multi-head latent attention, which saves memory during execution relative to other variants of attention. The authors compared their implementation to the variant GQA used in Qwen 2.5 72B and Llama 3.1 405B. Their method (70 kilobytes per token) used far less memory than Qwen-2.5 (328 kilobytes per token) or Llama 3.1 (516 kilobytes per token).
Behind the news: DeepSeek-V3 made waves when it was released in December. It performed better than Llama 3.1 405B, the leading LLM at the time, but its training cost was an astonishing $5.6 million, compared to the usual tens to hundreds of millions of dollars. Some observers were skeptical of the reported cost, pointing out that the $5.6 million dollar figure doesn’t include salaries, data acquisition and annotation, processing failed training runs, and other research and development costs. In addition, the cost of training DeepSeek-R1 remains unknown.
Why it matters: Traditionally, only companies with large budgets and vast resources could afford to train state-of-the-art models. DeepSeek changed that but didn’t explain how when it released its models. By sharing the details, the company has empowered a wider range of teams to improve the state of the art.
We’re thinking: Shortly after DeepSeek-R1 was released, some engineers claimed — without presenting evidence — that DeepSeek had copied their work. DeepSeek’s disclosure of its training methods should lay to rest any remaining questions about this. Its work was truly innovative, and we applaud its release of key technical details.

Did GPT-4o Train on O’Reilly Books?
A study co-authored by tech-manual publisher Tim O’Reilly shows that OpenAI trained GPT-4o on parts of his company’s books that were not made freely available.
What happened: O’Reilly, computer scientist Sruly Rosenblat, and economist Ilan Strauss found that GPT-4o was able to identify verbatim excerpts from dozens of O’Reilly Media books that the company kept behind a paywall, indicating that the books likely were included in the model’s training data.
How it works: The researchers adapted the DE-COP method to compare how well GPT-4o, GPT-4o-mini, and GPT-3.5 Turbo recognized paywalled excerpts versus freely available excerpts from the same books.
- The team selected 34 O’Reilly Media books and divided them into roughly 14,000 paragraphs.
- They labeled the paragraphs private (paywalled) or public (when O’Reilly Media publishes a book, it distributes freely on the web chapters 1 and 4 as well as the first 1,500 characters of other chapters). They also labeled the paragraphs according to whether they were published before or after the models’ knowledge cutoff dates.
- The team built multiple-choice quizzes, each composed of a verbatim paragraph and three paraphrased versions generated by Claude 3.5 Sonnet. The researchers ordered the paragraphs and paraphrases in all permutations to eliminate potential position bias.
Results: The authors asked each model to identify the verbatim paragraph and calculated each model’s percentage of correct responses. Then they averaged each model’s accuracy per book and converted the averages into AUROC scores that measure how well a model distinguished books available prior to its knowledge cutoff (potentially included in the training set) from those that weren’t available at the time. 50 percent AUROC indicates random chance, while higher scores indicate higher accuracy.
- GPT-4o tended to recognize O’Reilly Media content whether or not it was public, but it recognized private paragraphs (82 percent AUROC) markedly more often than public paragraphs (64 percent AUROC).
- GPT-4o-mini’s performance was nearly random for both private (56% AUROC) and public material (55% AUROC). The researchers hypothesize that either (i) the model’s smaller size may limit its ability to memorize or (2) OpenAI may reserve premium data to train larger models.
- The earlier GPT-3.5 Turbo recognized public paragraphs (64% AUROC) more often than private paragraphs (54% AUROC), which suggests that it was trained predominantly on freely available data.
Yes, but: Newer large language models are better at distinguishing human-written from generated text, even if it wasn’t in their training sets. For instance, given paragraphs that were published after their knowledge cutoffs, GPT-4o returned scores as high as 78 percent AUROC. The authors note that this may challenge their conclusions, since they interpret high scores to indicate that a model saw the text during training. Nonetheless, they argue that their approach will remain valid while scores for both text that was included and text that was excluded from training sets remain under 96 percent AUROC. “For now,” they write, “the gap remains sufficiently large to reliably separate the two categories.”
Behind the news: Historically AI developers have trained machine learning models on any data they could acquire. But in the era of generative AI, models trained on copyrighted works can mimic the works and styles of the works’ owners, creating a threat to their livelihoods. Some AI developers have responded by regarding data that’s freely available on the web as fair game, and material that’s otherwise protected as off-limits for training. However, datasets that include ostensibly private data are widely circulated, including LibGen, which includes all 34 of the O’Reilly Media titles tested in this study. Moreover, unauthorized copies of many copyrighted works are posted without paywalls or even logins, making it possible even for web scrapers that crawl only the open web to download them. Google and OpenAI, which is currently embroiled in lawsuits by authors and publishers who claim it violated copyrights by training models on copyrighted works, recently lobbied the United States government to relax copyright laws for AI developers.
Why it matters: The AI industry requires huge quantities of high-quality data to keep advancing the state of the art. At the same time, copyright owners are worried that models trained on their data might hamper their opportunities to earn a living. AI developers must find fair ways to respond. As O’Reilly points out, exploiting copyrighted works instead of rewarding their authors could lead to an “extractive dead end” that ultimately diminishes the supply of the high-quality training data.
We’re thinking: We have learned a great deal from O’Reilly Media’s books, and we’re grateful to the many authors, editors, graphic artists, and others who produce them. Meanwhile, it’s time for the U.S. Congress — and legislators internationally — to update copyright laws for the era of generative AI, so everyone knows the rules and we can find ways to follow them.